《Learning Spatiotemporal Features with 3D Convolutional Networks》
这是G. Zhu等人于2017年发表于IEEE ACCESS的一篇关于深度学习用于手势识别的文献,提出了3D卷积神经网络与卷积LSTM的结合使用,进行时空特征提取。
1. 主要内容:
- 提出了一个多模手势识别,基于3D卷积以及conv LSTM;
- 首先用3D卷积学习短期时空特征;
- 然后时空卷积LSTM学习长期时空特征,基于先前提取出的短期特征;
- 分别在IsoGD和SKIG大规模数据集上取得了最优的成绩
2. 介绍:
手势识别旨在识别和理解人体的有意义的运动,有效的手势识别仍然是一个非常具有挑战性的问题,部分原因是文化差异,各种观察环境,噪声,图像中手指相对较小的尺寸,词汇外动作等。
传统方法:隐马尔可夫模型,粒子滤波,有限状态机和连接模型。
由于上述具有挑战性的因素,手工制作的特征不能完全满足实际手势识别系统的要求。
思路:手势识别通常基于视频或图像序列–>时间信息在手势识别过程中起着关键作用–>复杂的背景会给手势识别带来更多挑战–>同时同步学习时空特征将为手势识别提供更多信息。
- 双流卷积网络分别从RGB和叠加的光流图像中提取空间和时间特征。
- LRCN首先从每帧中学习空间特征,然后使用RNN基于空间特征序列学习时间特征。
- VideoLSTM使用卷积LSTM网络从先前提取的二维空间特征中学习时空特征。
这三种代表性的方法分别或不同阶段地学习时空特征。而本文提出的方法则是同步的。
- 首先,利用3D CNN从输入视频中提取短时空特征。
- 然后利用conv LSTM进一步学习长时空特征。
- 最后,用SPP来规范最终分类的时空特征。
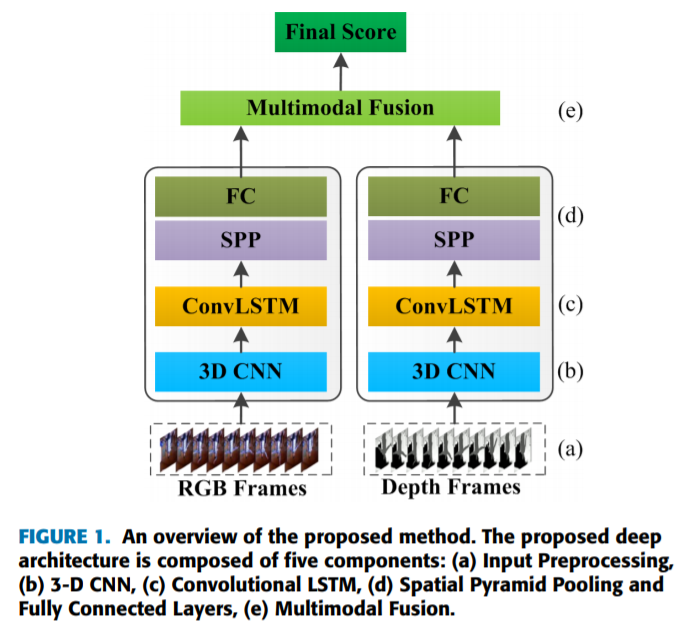
本文主要贡献:
- 针对手势识别,提出基于3D CNN和卷积LSTM的方法;
- 对多模式数据之间的微调进行评估,并将其视为可选技巧,以防止在没有预先训练的模在时出现过拟合;
- 在IsoGD和SKIG数据集中展现较好的性能;
3. 相关研究:
A. 基于人工提取特征的方法
B. 基于神经网络的方法
4. 创新点:
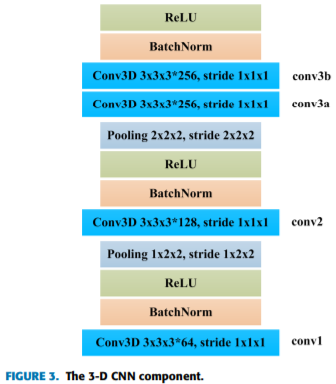
- 3D-CNN
- 参照C3D网络设计(具体看论文《learning spatiotemporal features with 3D convolutional networks》);
- 使用Batch normalization 加速训练;
- 3D-CNN组件只能学习短时空特征;
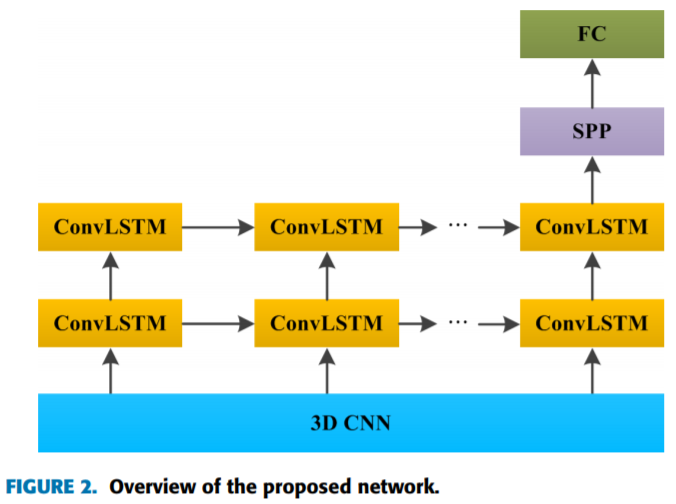
- B. Convolutional LSTM
- 传统的全连接LSTM不需要考虑空间相关性;
- 卷积LSTM(ConvLSTM)同时具有输入状态和状态转换的卷积结构,能够针对时空关系很好地建模;
- ConvLSTM的输入X1,X2…Xt,神经元状态C1,C2,C3….Ct和隐藏层状态H1,H2,H3….Ht以及各个门(gates)都是三维张量,并且最后两维是空间维度;
公式:
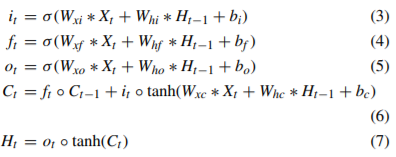
这里的*表示卷积。 - Spatial Pyramid Pooling
- 3-D CNN仅在空间域上以小的4的比例缩小图像,并且ConvLSTM组件不改变特征图的空间大小
- 空间金字塔池SPP插入ConvLSTM和全连接(FC)层之间以降低维度
- Multimodal Fusion(多模式融合)
- 采用后期多模态融合,并通过平均值融合不同网络的预测得到最终的预测分数。
5. 网络结构:
先进行输入预处理:方法一:将每个手势序列分成具有固定长度的剪辑,但是一个剪辑不能表示整个手势。方法二:将每个手势序列下采样到固定长度L中。
使用方法二,同时,采用时间抖动策 略的均匀采样来增强数据集。
$Idx_i= \frac{S}{L}*(i+jit/2)$
6. 实验设置:
- 无预训练,从零开始;
- Batch normalization加速训练,使用更高学习率且需要更少的时间;
- 初始学习率设置为0.1,并且每15,000次迭代降至1/10;
- 权重衰减初始化为0.004,并在40,000次迭代后减小至0.00004;
- 使用IsoGD,需要60,000次迭代;
- 基于IsoGD的预训练模型,针对SKIG进行了微调;
- Batch Size大小为13;
- 每个剪辑的时间长度为32帧,每个图像的裁剪大小为112;
7. 结果:
在IsoGD上的实验结果:
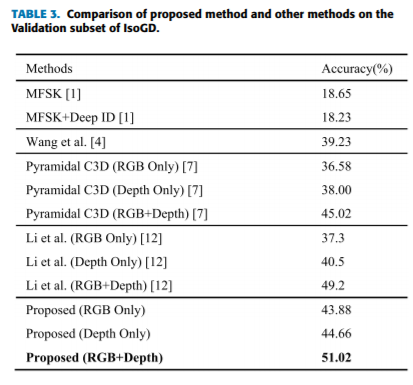
在SKIG的结果:
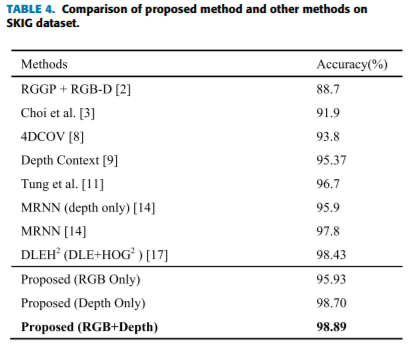
8. 总结:
本文提出了一种基于三维卷积神经网络和卷积长短期记忆(LSTM)网络的多模式手势识别方法。结果表明,同时学习时空特征比连续或单独学习手势识别的空间和时间特征更合适。
三维卷积神经网络适合学习短时空特征,而卷积LSTM网络适合长时空学习。