《You Only Look Once: Unified, Real-Time Object Detection》
这是Joseph Redmon等人于发表于CVPR 2016的一篇关于目标检测的文献,提出了目标检测领域经典的YOLO模型,一种端到端的实时目标检测方法。
1. 主要内容:
- 将目标检测任务作为一个回归问题,而不像先前的方法那样改造分类器用来识别;
- 使用单个神经网络就可以从输入图像直接预测边界框和分类概率;
- YOLO的速度非常快,在 TITAN X GPU上的实时处理速度达到了45fps;
- YOLO的泛化能力强,效果比其他目标检测方法(DPM、R-CNN)更好;
2. 介绍:
现有的物体检测方法,都是将分类器改造,去评估一张图像的各种不同尺度的区域内,是否包含物体以及物体是种类。比如DPM对整张图片使用一个均匀移动的滑动窗口进行分类。最近的 R-CNN采用的是 region proposals 的方法,生成潜在(可能包含待检测物体)的边界框,再使用分类器去判断每个边界框里是否包含有物体,物体类别的概率和confidence。因为每个组件都需要分开训练,所以这种方法过于复杂,很难优化。

本文则将目标检测定义为单个的回归问题,直接从图像像素得到边界框的坐标和类别的概率。YOLO非常简洁(如上图所示),只用一个卷积网络就可以同步地预测多个边界框的位置和类别概率。YOLO在整张图片上面训练,可以直接优化检测性能。这种统一架构有以下几个有点:
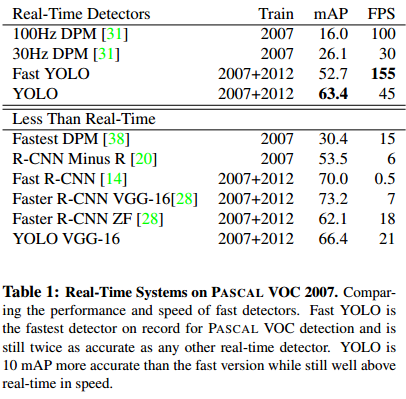
A. YOLO特别快。在 Titan X 上,不需要经过批处理,YOLO处理速度可达到45fps,Fast-YOLO可达到150fps。同时,mAP是其他实时检测系统的两倍。
B. YOLO在推理时使用的是全局图像,与使用滑动窗口和region proposal方法不同,You Only Look Once。YOLO 的background error(False Positive)比Fase R-CNN少一半
C. YOLO 学到物体更泛化的特征表示。
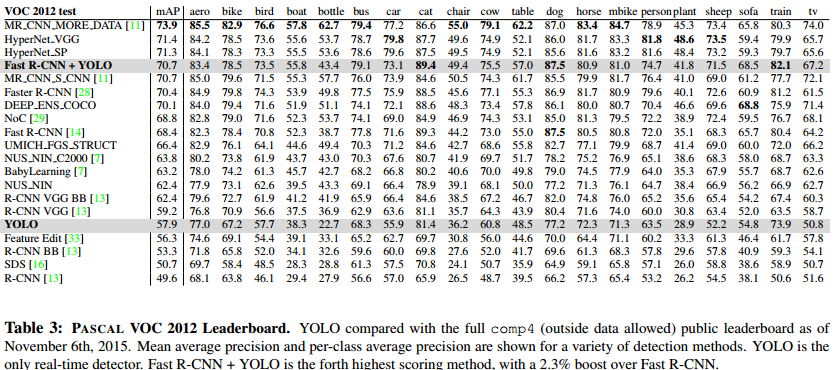
但是,YOLO的准确性仍然低于最好的检测系统。即便它能够快速地识别图像中的目标,它很难非常准确的定位某些物体,尤其是小物体。
3. 方法:
本文将目标检测的各个组件统一成单个神经网络。YOLO可以实现端到端的训练和预测,同时保持较高的准确率。 该系统将输入图像分成S×S的栅格(grid cell),如果一个物体的中心掉落在一个栅格内,那么这个栅格就负责检测这个物体。每个栅格预测出B个边界框以及这些边界框的得分(confidence score),得分反映了这个框内含有物体的可能性。定义这个confidence的公式为:
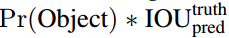
每个边界框都包含5个预测值:x,y,w,h和confidence。x,y就是bounding box的中心坐标,与grid cell对齐(即相对于当前grid cell的偏移值),使得范围变成0到1;w和h进行归一化(分别除以图像的w和h,这样最后的w和h就在0到1范围)。 每个栅格都预测C个类别概率,表示一个栅格在包含物体的条件下属于某个类别的概率:
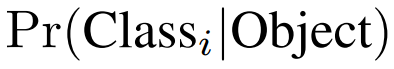
在测试阶段,将每个栅格的 conditional class probabilities 与每个边界框的得分相乘:
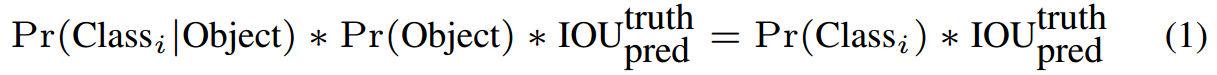
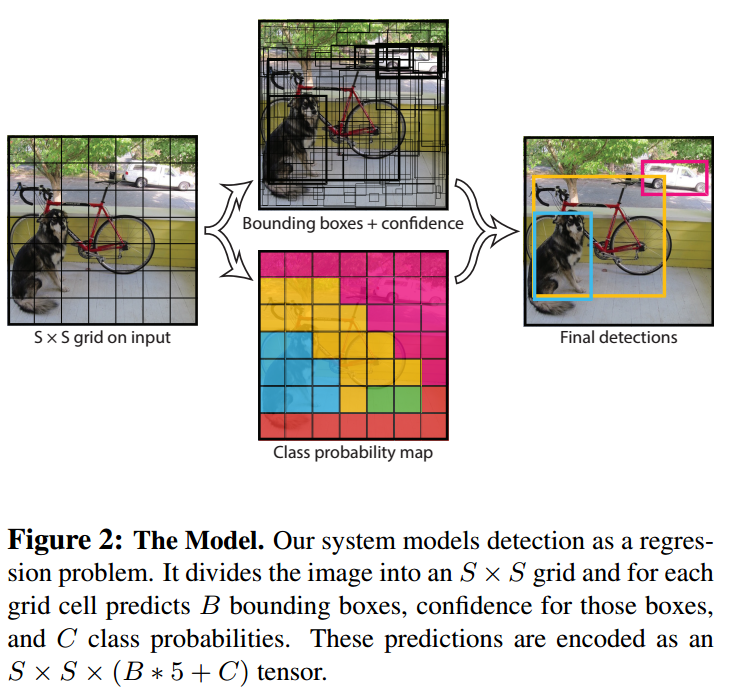
网络架构设计
本文使用卷积神经网络构成这个模型。开始的卷积层用于从图像中提取特征,之后的全连接层用来预测输出的概率和坐标。网络架构来源于GoogLeNet。该网络拥有24个卷积层和2个全连接层。但是模型并没有使用inception模块,只用了1×1的reduction layer后面跟着3×3的卷积层。整体的网络如下图所示:

Fast YOLO与YOLO除了将24卷积层变成9层以及更少的滤波器以外,其他的训练测试参数都相同。 网络的最终输出为7×7×30的张量。
4. 实验设置:
采用ImageNet 1000-class 数据集来预训练卷积层。预训练阶段,采用网络中的前20卷积层,外加平均池化层和全连接层。模型训练了一周,获得了top-5 准确率为0.88(ImageNet2012 validation set),与GoogleNet模型准确率相当。 然后,将模型转换为检测模型。作者向预训练模型中加入了4个卷积层和两层全连接层,提高了模型输入分辨率(224×224->448×448)。顶层预测类别概率和bounding box协调值。bounding box的宽和高通过输入图像宽和高归一化到0-1区间。顶层采用linear activation,其它层使用 leaky rectified linear。 作者采用sum-squared error为目标函数来优化,增加边界框坐标权重,减少置信度权重,实验中,本文使用两个参数来解决此问题,设定lambda(coord)=5 和lambda(noobj)=0.5。
数据集:PASCAL VOC2007和PASCAL VOC2012
训练135轮,batch size为64,动量为0.9,学习速率延迟为0.0005。学习策略为:第一轮,学习速率从0.001缓慢增加到0.01(因为如果初始为高学习速率,会导致模型发散);保持0.01速率到75轮;然后在后30轮中,下降到0.001;最后30轮,学习速率为0.0001。此外,本文还采用了dropout和数据增强来预防过拟合。dropout值为0.5;数据增强包括:随机裁剪,旋转,调整曝光和饱和度。
5. 结果:
6. 总结:
A. 本文介绍了YOLO,一个统一的目标检测模型,该模型很容易建立且可以直接在完整图像上训练。不同于基于分类的方法,YOLO的整个模型是一起训练的,损失函数和检测性能直接相关。
B. Fast YOLO是最快的通用目标检测方法,YOLO则是最优的快速、稳定的实时目标检测方法。