主流人脸识别的原理(以GitHub项目face_recognition为例)
GitHub项目地址face_recognition
该项目目前star数超过3万,是GitHub上最主流的人脸识别工具包之一。Face_recognition主要参考了OpenFace项目以及谷歌的facenet。其主页的介绍如下:
本项目是世界上最简洁的人脸识别库,你可以使用Python和命令行工具提取、识别、操作人脸。
本项目的人脸识别是基于业内领先的C++开源库dlib中的深度学习模型,用Labeled Faces in the Wild人脸数据集进行测试,有高达99.38%的准确率。但对小孩和亚洲人脸的识别准确率尚待提升。
Labeled Faces in the Wild是美国麻省大学安姆斯特分校(University of Massachusetts Amherst)制作的人脸数据集,该数据集包含了从网络收集的13,000多张面部图像。
本项目提供了简易的face_recognition命令行工具,你可以用它处理整个文件夹里的图片。
本文主要讲解face_recognition的原理,介绍一下人脸识别的完整过程。完整的人脸识别任务需要解决以下关键问题——
人脸识别关键问题:
- 找出所有人脸
- 在不同光线和方向下识别出同一人脸
- 找出每张脸与他人的区别
- 将人脸与已知人脸比较以确定其身份
人脸识别步骤:
1. 人脸检测
要想识别人脸,首先需要在图像或者视频帧中找到所有人脸的位置,并将人脸部分的图像切割出来。
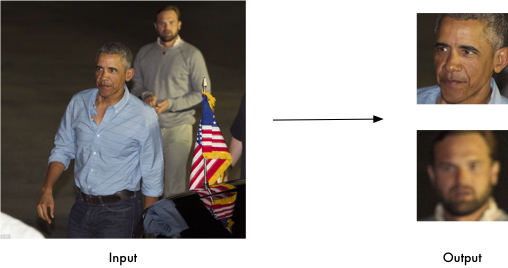
可以使用方向梯度直方图(HOG)来检测人脸位置。先将图片灰度化,因为色彩对于找到人脸位置并无明显作用,接着计算图像中各像素的梯度。
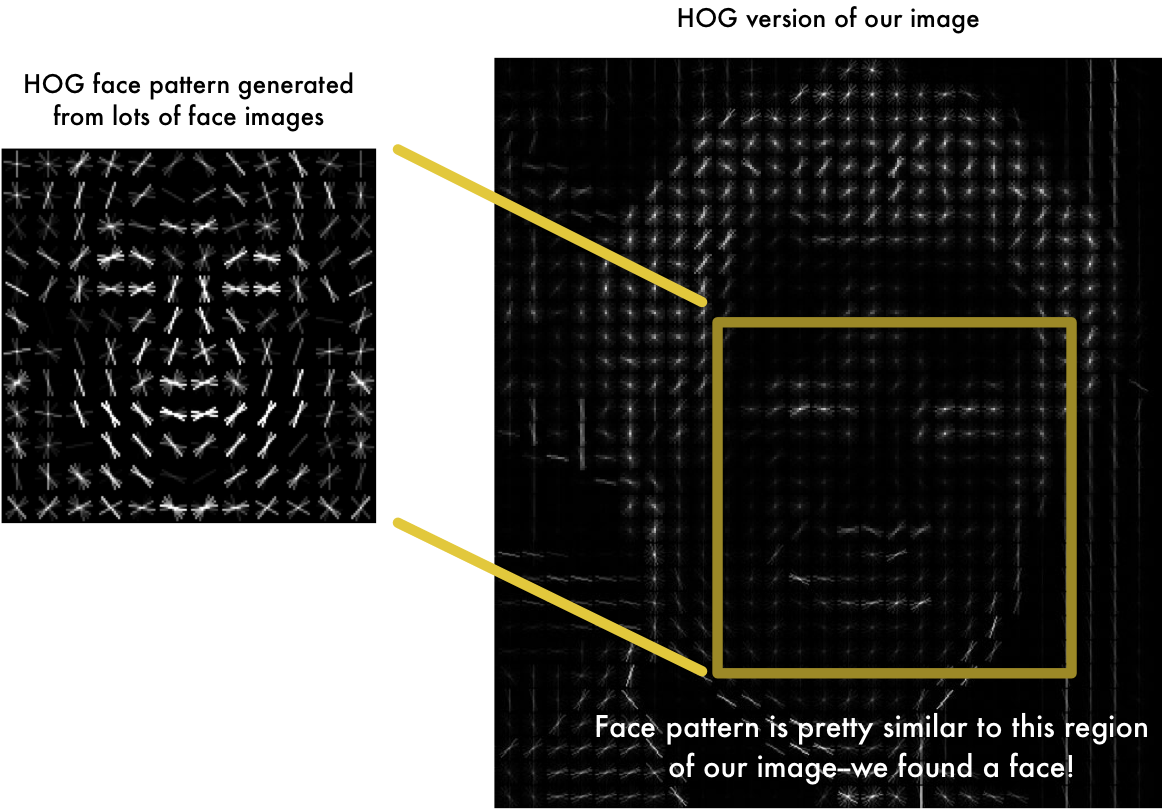
通过将图像变换为HOG形式,我们就可以提取图像的特征,从而获取人脸位置。
2. 人脸对齐
一张图片中的人脸可能是倾斜的,或者仅仅是侧脸。为了方便给人脸编码,需要将人脸对齐成同一种标准的形状。
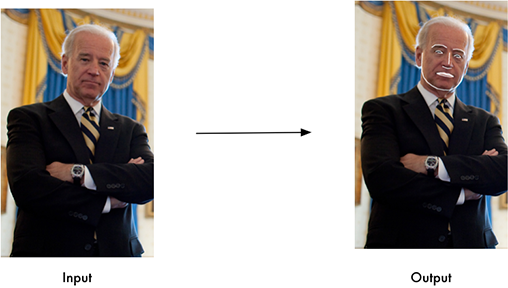
人脸对齐的第一步就是人脸是特征点估计。Dlib有专门的函数和模型,能够实现人脸68个特征点的定位。
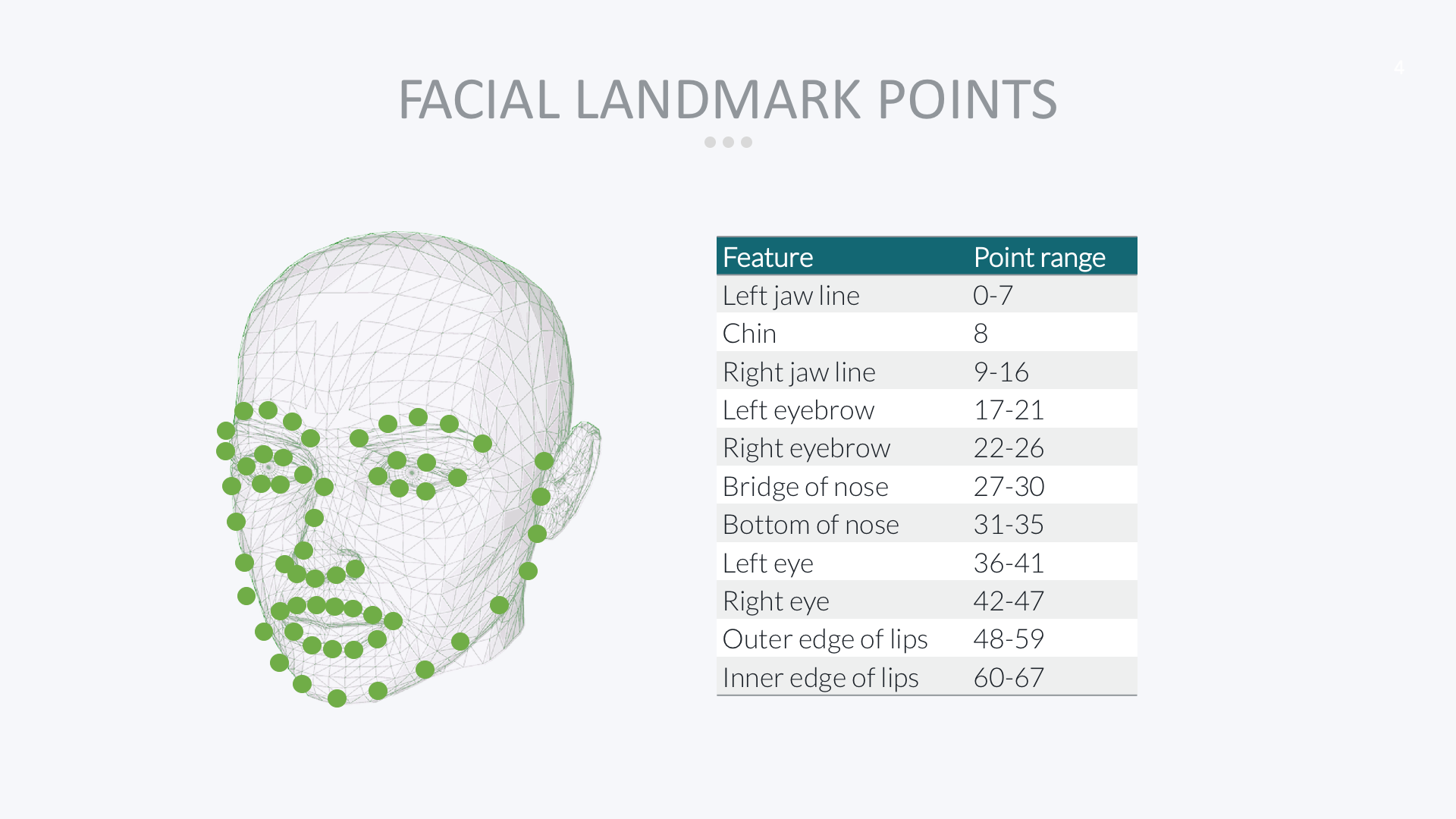
找到特征点后,就可以通过图像的几何变换(仿射、旋转、缩放),使各个特征点对齐(将眼睛、嘴等部位移到相同位置)。
3. 人脸编码

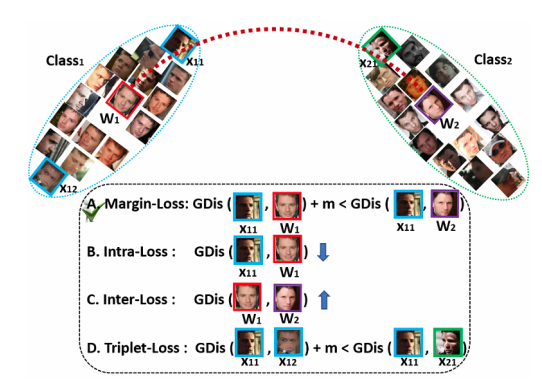
训练一个神经网络,将输入的脸部图像生成为128维的预测值。
训练的大致过程为:将同一人的两张不同照片和另一人的照片一起喂入神经网络,不断迭代训练,使同一人的两张照片编码后的预测值接近,不同人的照片预测值拉远。也就是减小类内距离,增大类间距离。具体算法参考facenet[3]。

4. 识别身份
预先将所有人的连放入人脸库中,全部用上述的神经网络编码为128维并保存。识别时,将人脸预测为128维的向量后,与人脸库中的数据进行比对。
比对方法有很多种,可以直接找出阈值范围内欧氏距离最小的人脸,或者训练一个末端的SVM或者knn分类器,直接生成人的代号(身份)。
knn分类器构建方法可参考这个代码。

整体的使用python实现人脸识别的代码可以参考使用OpenCV,Python和深度学习进行人脸识别。
参考文献
- Mark Farragher, Detect Facial Landmark Points With C# And Dlib In Only 50 Lines Of Code.
- Adam Geitgey, Machine Learning is Fun! Part 4: Modern Face Recognition with Deep Learning.
- Schroff, Florian, Dmitry Kalenichenko, and James Philbin. “Facenet: A unified embedding for face recognition and clustering.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
- Deng, Jiankang, et al. “Arcface: Additive angular margin loss for deep face recognition.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
- https://www.pyimagesearch.com/2018/06/18/face-recognition-with-opencv-python-and-deep-learning/
- https://github.com/ageitgey/face_recognition