《Learning Spatiotemporal Features with 3D Convolutional Networks》
这是Du Tran于2014年发表于CVPR的一篇关于深度学习用于动作识别的文献,第一次提出了 C3D Model,即三维卷积神经网络。
1. 主要内容:
- 展示3D卷积网络优于2D网络,可以同步地对动作和特征建模;
- 通过实验证明3×3×3的卷积核最有效;
- 提出了一种全新的网络架构,优于或接近4个不同任务和6个不同基准的最佳方法。
2. 相关研究:
此文章研究思路为:深度学习的提出使得提取图像特征变得容易了——> 但是传统的深度学习包括卷积神经网络不能用于视频中的特征识别——> 提出了一个能同时识别视频的时空特征的三维卷积网络。
- STIPs:通过将Harris角探测器扩展到3D来进行动作识别;
- Cuboids特征用于行为识别 ;
- iDT,hand-crafted特征等等;
- 依赖强大的GPU,进行深度学习(会产生大量的训练数据)。
3. 创新点:
- 2D卷积无论应用于单张图片还是多张图片,输出都是二维结果,因此用于视频识别时就会丢失时间序列的信息
- 3D卷积刚好很好地解决了这个问题,它同时保留了时间信息与空间信息;
- 池化层采用相同操作,池化核改为三维;
- 只调整3D卷积核的时间维度的长度,保持空间维度为3×3不变。
4. 网络结构:
该网络包含8个卷积层,5个池化层,2个全连接层和1个softmax输出层。
- 所有层的3D卷积核的尺寸为 3×3×3,步长为 1;
- 一层池化层的尺寸为 1×2×2,步长为 1,其余池化层的尺寸为 2×2×2,步长为 2;
- 视频都被调整大小为128×171,分开成为互不重叠的16片段并被作为网络输入,即3×16×128×171 (3为RGB通道);
- 5个卷积层的滤波器数量分别为64,128,256,256,256. 所有卷积层都有合适的padding;
- 使用最小梯度下降法;
- 起始学习率为0.003.学习率会每4个epoch而衰减十倍。
5. 实验设置:
- sports-1M数据集,每一帧的尺寸被归一化为 128×171,使用了0.5几率随机水平翻转的数据增强的方法。
- batchsize设为30,初始学习率为0.003。
- 分别对训练过程中始终不变的时间维度长度,与变化的时间维度长度分别训练。不变的长度为别为1,3,5,7,变化的时间核长度分为递增3-3-5-5-7与递减7-5-5-3-3
6. 结果:
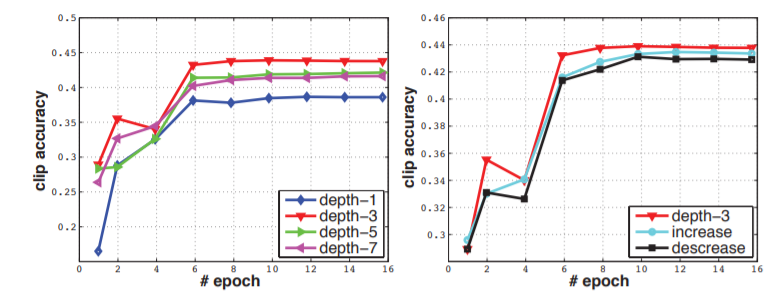
作者不断修改卷积核的时间维度大小,测试结果表明,当时间维度为3时,表现最好。即:3D卷积核大小应该为3×3×3.
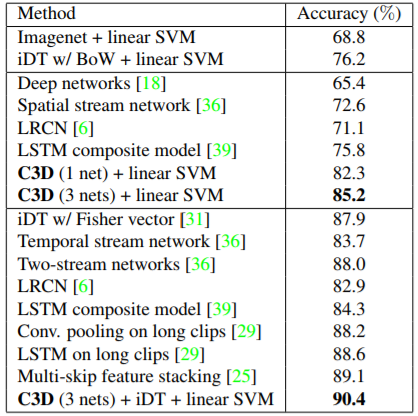
在UCF101和Sports-1M数据集上,C3D的准确率均高于其他方法。
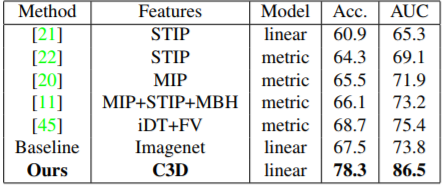
使用C3D进行动作识别相似性标定,效果最好。
7. 总结:
本文尝试解决了在大范围数据库中学习视频的时间空间特征的问题。通过系统一学习找到了最好的时间核(3,3,3),并展示了它在视频识别中的优秀表现。同时,C3D在动作特征识别中,具有更强的泛化性和压缩性。
8. My Implementation
使用TensorFlow复现的代码点击 这里
不加载预训练模型,使用OpenCV resize原始图像,保存为float64形式,训练8000轮,BATCH_SIZE=10,训练结果如下图:
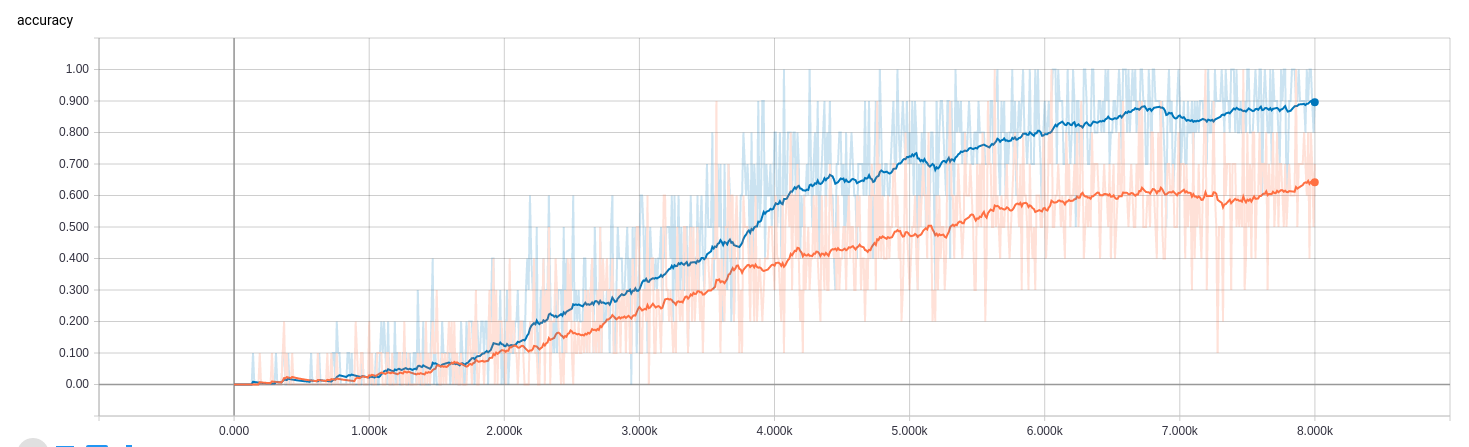
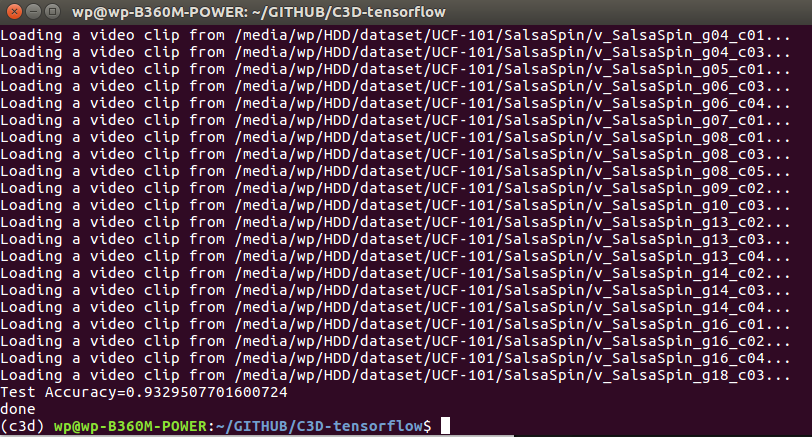
最终准确率可达64%

由于并未加载预训练模型,且只训练了8000轮,这个结果已经较为满意了。如果加载预训练模型,即使用sports-1M微调过的模型,最终在UCF101上的准确率可达93%。