《Learning Spatio-Temporal Features with Two-Stream Deep 3D CNNs for Lipreading》
这是Xinshuo Weng等人于2019年发表于BMVC的一篇关于唇语识别的文献,提出了使用双流3D卷积神经网络进行唇语的时空特征提取。
1. 主要内容:
- 使用双流输入的深度3D CNN模型进行前段提取特征;
- 在LRW上分析评估了多种前后端模型组合的表现;
- 在大规模图像/视频数据集上预训练后的深度3D CNN可以提高识别准确率;
- 仅仅使用光流作为输入就可以得到与灰度图输入相媲美的结果,而双流输入可以极大地提升性能;
- 本文提出的双流I3D前端+双向LSTM后端比当时最好的模型准确率提升了5.3%;
2. 介绍:
本文之前最好的唇语识别方法是端到端神经网络的使用,包括一个浅层的(大约3层)3D CNN+深层的2D CNN作为前端来提取视觉特征,然后使用RNN(比如双向LSTM)作为后端来进行分类。
单词级别的唇语识别是一项困难的任务,因为它的敏感性。不同的字幕有时可以产生同样的嘴唇移动(比如p和b)。这些字母很难单独通过视觉线索区分。但是,人们通过词语中邻近字母的内容解决这种问题(单词级唇语识别)。所以,对帧之间的时间信息建模是很重要的。
传统方法:研究人员用两级输入,包括从唇语区域的特征提取以及使用序列模型分类,这两个步骤是独立的。最普遍的特征提取方法是使用DCT(离散余弦变换)进行降维/维度压缩,之后再使用序列模型,如HMM(隐马尔科夫模型)对上一级提取出的特征进行时域建模,从而进行分类。如下图左。
最近最好的研究成果,使用了端到端的深度学习。和传统相似,裁剪后的唇部图像序列喂入前端网络提取特征,然后送入后端进行时域建模从而实现分类。如下图中间。不同之处在于通过loss算出的梯度可以从后端传播到前端,所以整个网络是端到端可训练的。因而学习出的特征相对于传统方法来说更适合唇语识别。现有的研究通常使用浅层3D CNN+深层2D CNN的结合作为前端,双向长短时间网络(Bi-LSTM)作为后端。
众所周知,基于图像的2D CNN特征提取并不能直接用于视频任务(比如唇语识别),使用3D CNN作为前端来学习时空特征更加合适。目前已有一些文章使用了3D CNN实现唇语识别,但大多使用了浅层3D CNN,根据作者推测,是因为深度3D CNN 由于过多的参数,很容易引起过拟合,导致表现不如浅层CNN。
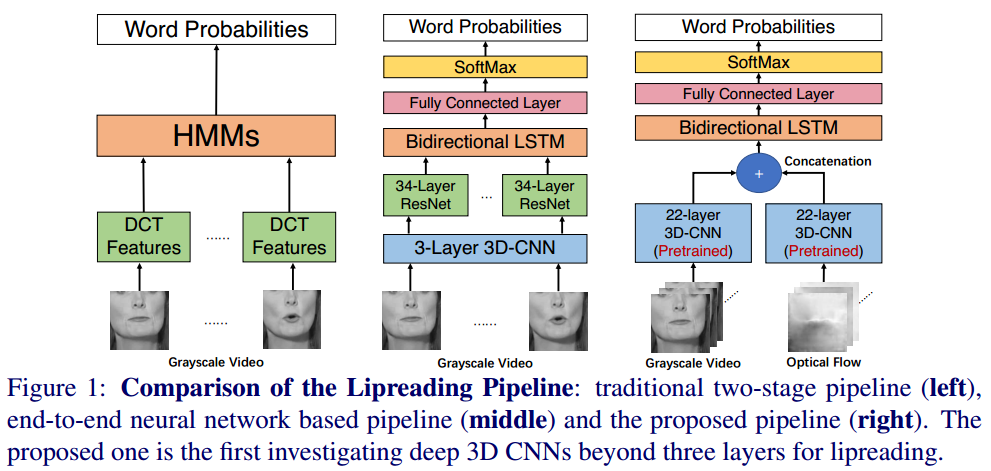
本文提出了第一个单词级基于深度3D CNN的唇语识别方法,如上图右。使用了22层的3D Inception Net作为前端,为了防止过拟合,使用了在ImageNet上预训练的模型膨胀为3D。根据文献《Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet?》的结论,3D CNN在其他数据集微调后可以提高准确率,因此本文在Kinetics数据集上预训练。本文在前后端评估了多种组合,以灰度图和光流作为输入。
3. 创新点:
主要贡献:
- 提出了第一个超过3层的深度3D CNN用作单词级唇语识别;
- 证明了预训练模型对于训练深度3D CNN的重要性;
- 展示了使用光流作为另一路输入可以大幅提升效果;
- 提出的I3D前端+BiLSTM后端取得了最好的表现;
4. 网络结构:
总体框架
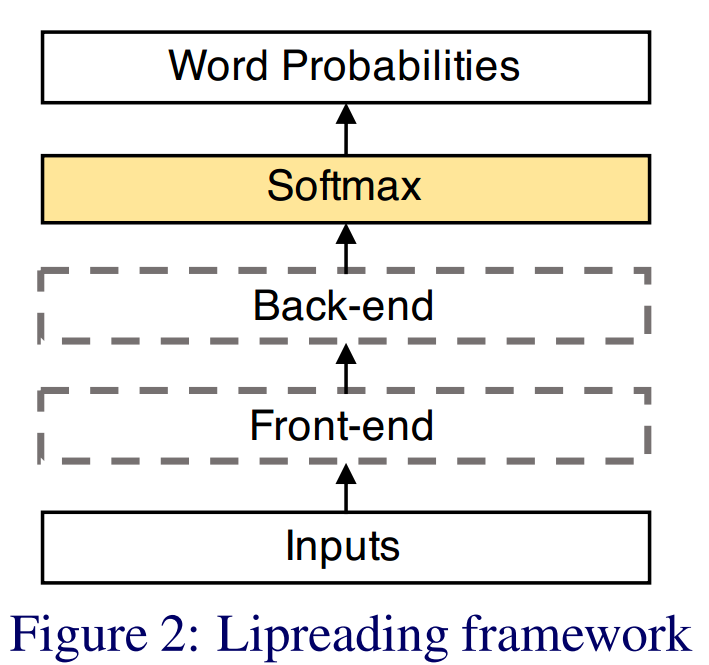
如图,唇语识别的框架由4个部分组成:
(a) 输入:一种图像序列,灰度或光流,或者二者结合;
(b) 前端模块:从输入提取特征;
(c) 后端末端:对时间建模,把特征汇总到一个向量;
(d) Softmax层:计算每个单词的概率;
前端模块:
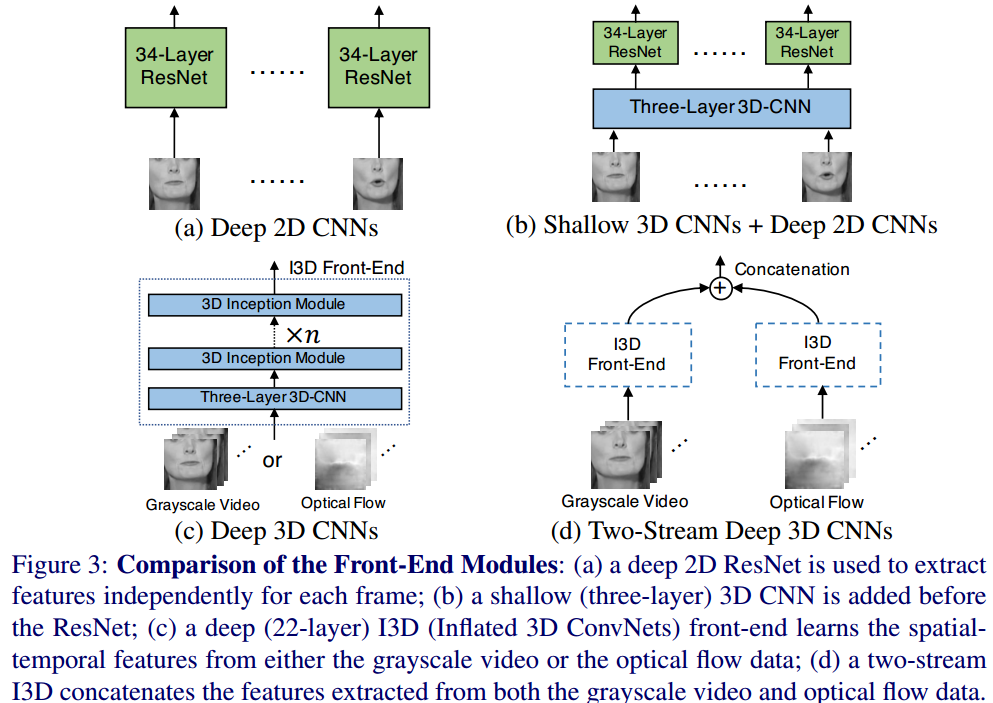
上图是本文四种前端模块的对比。
图a:使用深度2D CNN提取特征,虽然2D CNN只能提取基于图像的信息,但是后端的RNN依然能够在某种程度上对时间信息建模。图a展示了34层ResNet,从灰度图提取特征。
图b:浅层3D CNN+深层2D CNN,先使用浅层3D CNN预处理灰度图像,然后再输入深层ResNet。众所周知3D CNN可以捕获短时动态特征,即使在后端有LSTM时依然有用。由于训练三维卷积核带来的大量参数很困难,唇语识别最优的方法只用了3层3D CNN。本文把灰度视频输入3D卷积层,核心数64/64/96,每层后面有batch normalization、ReLU、3D Maxpooling,提取出的特征再给后面的34层ResNet处理。
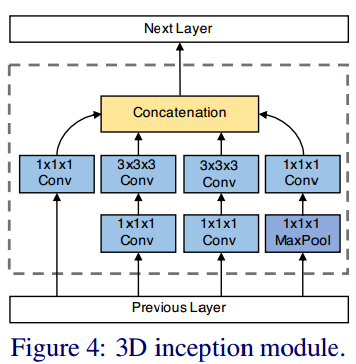
图c:深度3D CNN。使用I3D,22层Inception。3D Inception模块见下图:
图d:我们期望深度3D CNN可以提取足够强大的特征,所以实际上可以将光流和灰度相结合,这被证明对于视频处理任务很有用。本文使用PWC-Net预先计算光流。然后两路分别输入I3D。
后端模块:
A. 1D 时域卷积层:
最简单,只要在时间通道上使用1维卷积操作。两层1D卷积,后面接一个全连接层,将向量的长度映射为单词的数量,从而计算每个单词的原始概率。
B. 双向LSTM:
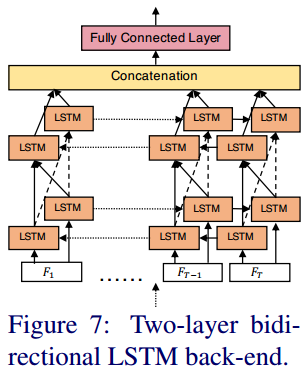
RNN可以对时间信息建模,LSTM被证明在解决梯度爆炸和梯度消失方面很有用。而双向LSTM可以同时具有每个时间点前向信息和反向信息。本文使用了两层双向LSTM,隐藏状态维度512,最后输入到全连接层,计算原始概率。
两轮预训练:
ImageNet上的权重预训练是很有效的,但不能直接使用,因为本文使用的是3D卷积核。本文将ImageN上预训练的模型膨胀为3D(即把2D filter上的权重重复N次以匹配时间维度)。但是这种预训练只能提取空间特征,而在大规模视频数据集上预训练可以提高效果,所以本文将模型在此在Kinetics数据集上做第二次预训练。
5. 实验设置:
数据集:LRW
预处理和数据增强:裁剪唇部区域112×112,随机镜像翻转、±5像素裁剪。对光流做同样类型数据增强以保持一致。 之后按照上一部分介绍的几种分类,分析不同组合的效果。
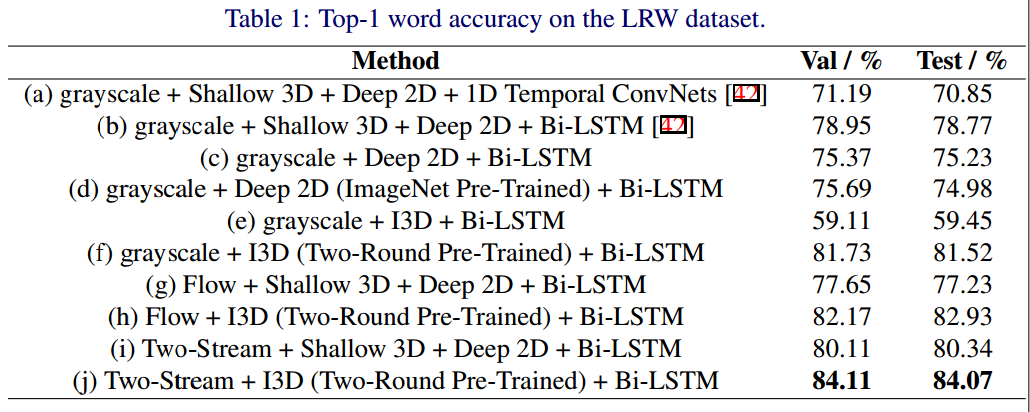
6. 结果:
在LRW上的实验结果:
7. 总结:
本文提出了第一个单词级唇语识别方法,使用超过3层是深度3D CNN。本文在LRW上评估了不同的前端后端组合,结果表明,经过两轮预训练,深度3D CNN前端的效果超过了之前的浅层3D CNN+深层2D CNN。光流和灰度输入对模型预测都是有效的,而二者结合的双流网络可以大幅提升效果。综上,本文的双流预训练I3D+BiLSTM比之前的最优模型性能提升5.3%。