目标检测经典算法总结
1. R-CNN:
从原图像中提取2000个候选区域。2000个候选区域由选择性搜索(selective search)算法产生。
选择性搜索:
(1)首先初始化多个候选区域;
(2)用贪心算法递归地将相似区域合并成较大区域;
(3)使用生成的区域去产生最终候选区域建议;
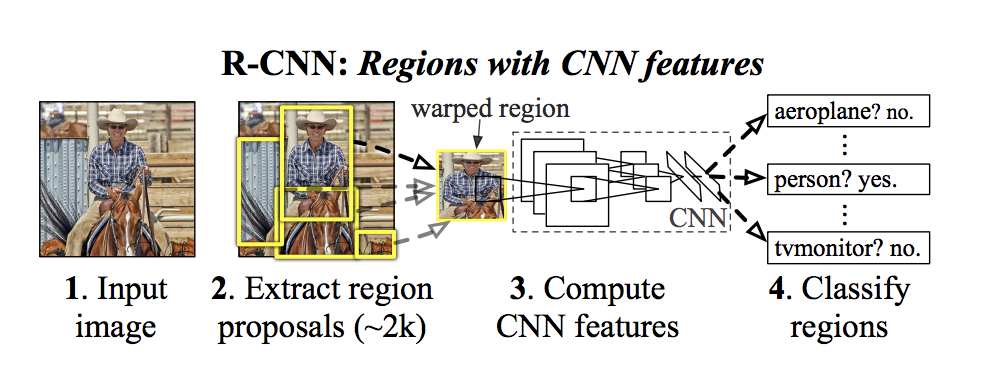
检测过程如上图所示:
- 将2000个候选区域分别调整成方形,喂入卷积神经网络;
- 由卷积神经网络产生4096维的特征向量;
- 把向量输入到支持向量机进行分类;
- 除此以外,还通过一个Bbox reg预测边界框的4个偏差值,提高边界框的精度。
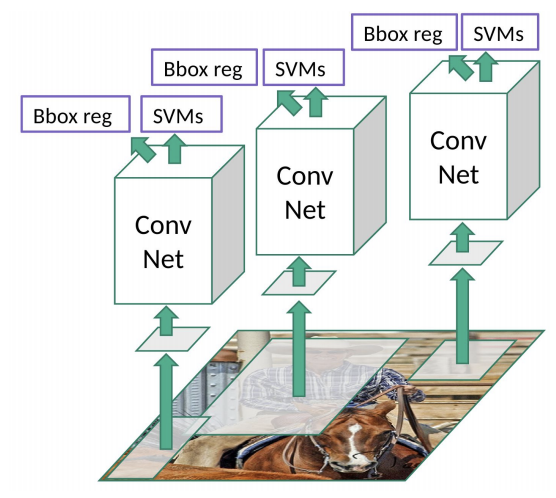
R-CNN存在的问题:
- 训练过程耗费大量时间(因为每张图像要分类2000个不同区域)
- 不适合实时目标检测(检测每张图像需要约47秒)
- 选择性搜索算法是固定的,不可训练(因此选择性算法可能产生不好的候选区域)
2. Fast R-CNN:(解决了R-CNN的许多缺点):
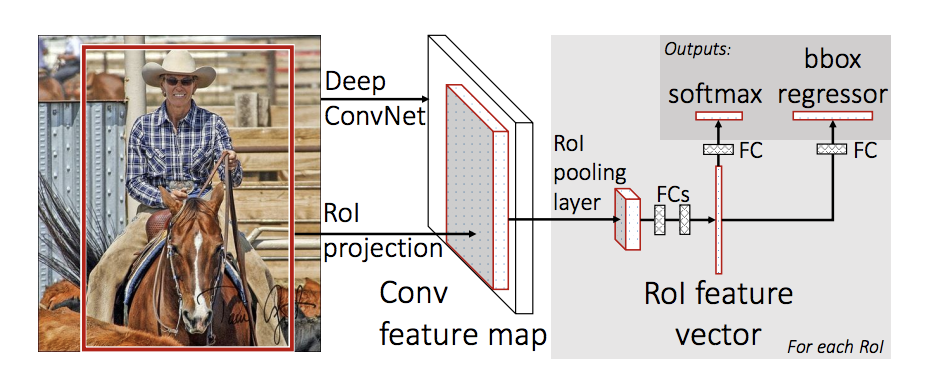
R-CNN是将各个小块的候选区域喂入卷积神经网络,而Fast R-CNN则是将整张图片都喂入神经网络。
检测过程如上图所示:
- 将原始图像输入卷积神经网络;
- 神经网络产生卷积特征图;
- 从卷积特征图中识别候选区域,并将其变为方形;
- 通过ROI卷积层把区域大小reshape为固定方形大小,喂入全连接层;
- 用softmax进行区域分类,用Bbox回归器预测4个偏差值;
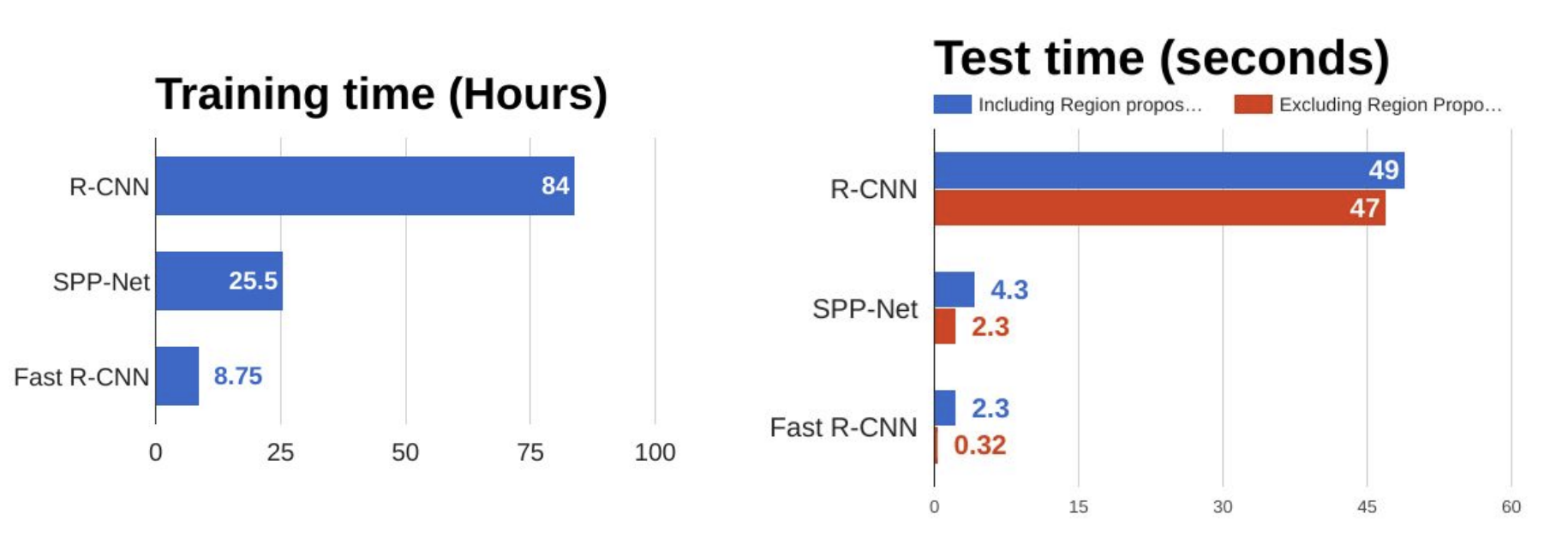
Fast R-CNN远快于R-CNN,其优势在于不用每次喂入2000个候选区域给卷积神经网络,每张图片只要一次卷积操作。
此外,由上图还可以看出,影响效率的瓶颈在于找到候选区域。
3. Faster R-CNN:
R-CNN和Fast R-CNN都使用了“选择性搜索”算法,这种算法很慢,耗费大量时间。因此Faster R-CNN摒弃了这种算法。
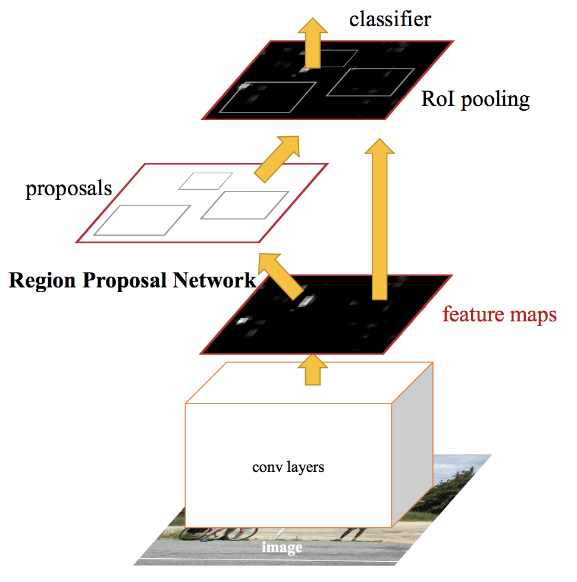
检测过程如图:
- 原始图像输入卷积神经网络,生成卷及特征图;
- 通过一个独立的网络预测候选区域;
- 使用ROI池化层把候选区域reshape为固定形状;
- 和Fast R-CNN一样用全连接层分类和预测偏差值。
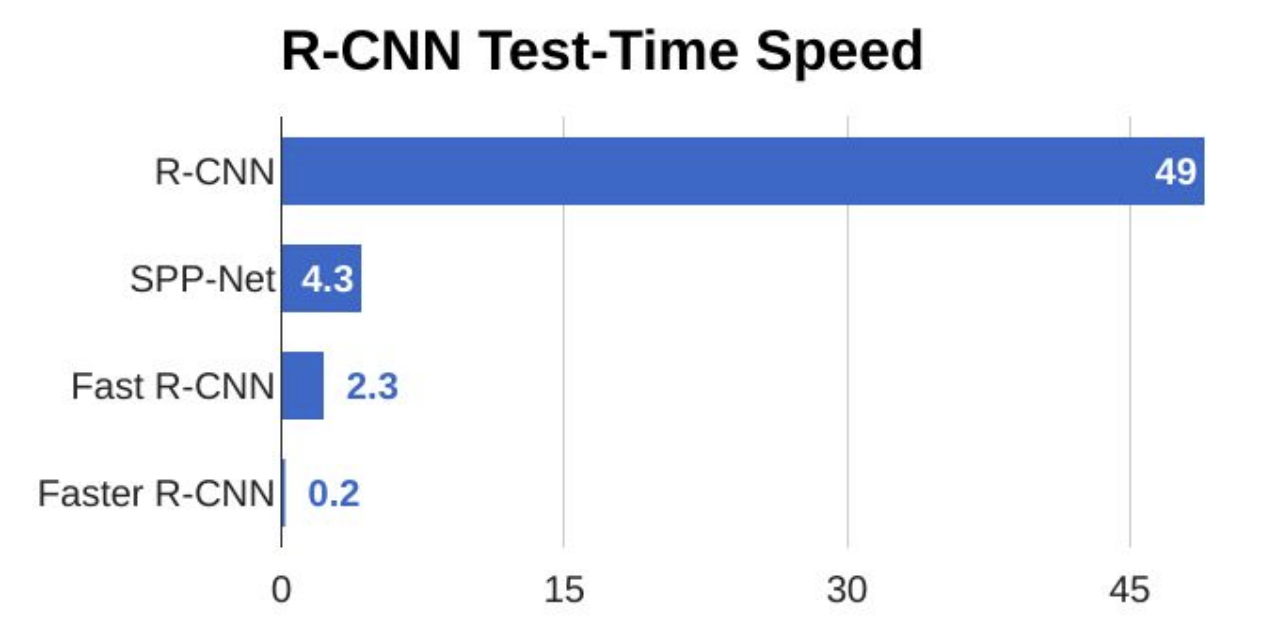
可以看出,Faster R-CNN远远比先前的算法快,因此适合作为实时物体检测。
4. YOLO:You Only Look Once:
上述3种算法:R-CNN,Fast R-CNN和Faster R-CNN都使用候选区域来定位物体,属于两阶段(One stage)目标检测。而YOLO只需单一的卷积神经网络即可预测边界框的位置和框内物体的类别。
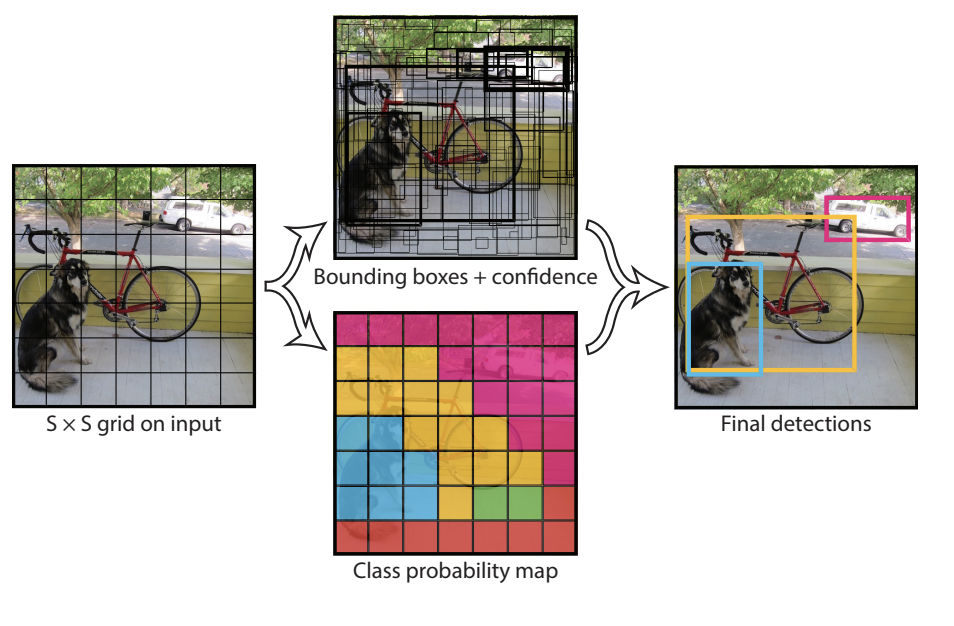
检测原理如上图所示:
- 把原始图像分割为S×S是单元格;
- 每个单元格负责预测m个不同尺度的边界框;
- 每个边界框会预测生成物体种类和偏差值;
- 设置阈值,选取所定位到的物体。
YOLO的特点:远快于两阶段算法(fps达到45),但是在检测小物体时性能较差。